
|
|
|
|
|
T-SQL Clauses: GROUP BY und HAVING
Geschrieben von: Christian Holm Die beiden T-SQL Clauses GROUP BY und HAVING, ob in Kombination verwendet oder nicht, dienen allgemein zum Gruppieren von Datenspalten. Dies geschieht in Verbindung mit dem SELECT Statement. Diese Gruppierung ist vor allem bei größeren ("rohen") Datenmengen von Vorteil, da hierbei die Daten schnell und übersichtlich in einzelne Gruppen gegliedert werden. Die dadurch durchgeführten Änderungen werden dabei nicht permanent in der Datenbank gespeichert. In diesem Artikel präsentiere ich Ihnen einmal die Basics über die beiden Clauses und werde dabei mit kleinen Beispielen die Theorie veranschaulichen. Die GROUP BY ClauseIn Verbindung mit einer (optionalen) Aggregate Function faßt die GROUP BY Clause die betroffenen Datenspalten im zurückgelieferten Ergebnis der Query (Datenbankabfrage) in einzelne Gruppen zusammen. Mit Aggregate Function ist eine Funktion gemeint, die eine Berechung/Manipulation (z.B. SUM, MAX, MIN) mit der angegebenen Spalte durchführt. Hierbei ist aber zu beachten, daß die GROUP BY Clause zwar die betroffene(n) Datenspalte(n) in einzelne Gruppen teilt, aber keine Sortierung durchführt. Daher sollte bei zusätzlicher Sortierungsanfordernis eine ORDER BY Clause verwendet werden. Weiters ist bei der Verwendung der Clause zu beachten, daß Spalten mit Datentyp ntext, text oder image nicht zum Gruppieren verwendet werden können. Der Gruppierungsarbeit sind aber auch Grenzen gesetzt. Die Größe der Datenspalten ist begrenzt, da max. 8060 Bytes im Zwischentabellenspeicher abgelegt werden können. Prinzipiell sieht die Clause in der Verwendenung so aus bzw. kann sie folgende (optionale) Argumente noch zusätzlich aufnehmen: GROUP BY ALL Ausdruck-Kommaliste (mit/ohne Aggregate Function) WITH CUBE / ROLLUP Hierbei bedeutet - wobei Angaben in Kursivschrift als optional gelten:
Sehen wir uns zu der GROUP BY Clause ein paar einfache Beispiele an. Die Queries wurden gegen die Northwind SQL-Datenbank gefahren. Wie Sie vielleicht wissen bietet der MS SQL Server u.a. ein bequeme Möglichkeit den Sytanx von Queries zu überprüfen und zugleich diesen gegen die Datenbank zu fahren - nämlich im SQL Query Analyzer. Die erste Aufgabe besteht darin, aus der Products Tabelle der Northwind Datenbank alle Produkte aufzulisten und die Summe der im Lager vorhandenen Einheiten zu ermitteln. Es ist nach dem Produktnamen zu gruppieren. Eine mögliche Lösung wäre: SELECT ProductName, SUM(UnitsInStock) AS 'Units In Stock' FROM Products GROUP BY ProductName Um das Ergebnis zu veranschaulichen, hier die Query und ein Auschnitt aus dem Ergebnis der Query: 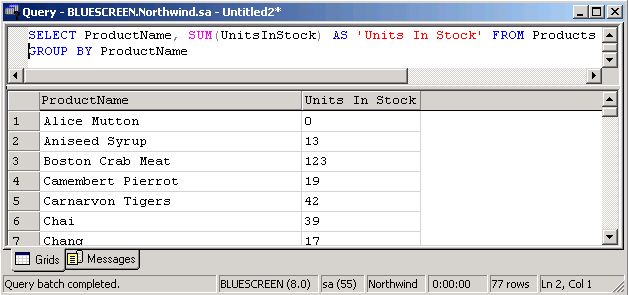
Als nächstes sollen der Produktname und die SupplierId wieder aus der Products Tabelle aufgelistet werden. Jetzt soll aber nach der SupplierID gruppiert und WITH CUBE verwendet werden: SELECT ProductName,SupplierId FROM Products GROUP BY SupplierId, ProductName WITH CUBE Dargestellt im SQL Query Analyzer sieht dies wieder so aus: 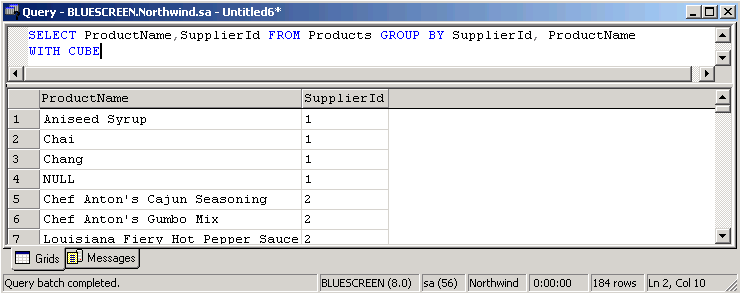
Weil wir schon bei CUBE sind, tauschen wir dies gegen ROLLUP und sehen uns das Ergebnis an: SELECT ProductName,SupplierId FROM Products GROUP BY SupplierId, ProductName WITH ROLLUP 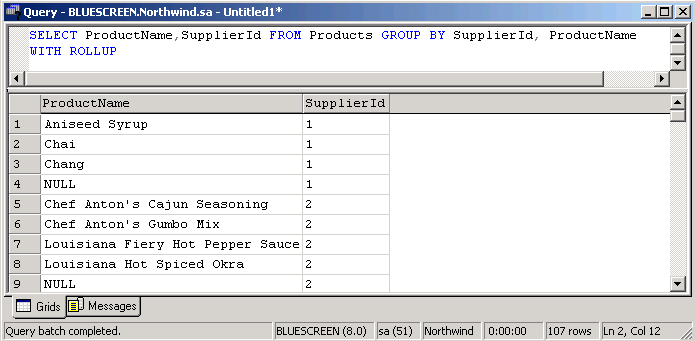
Auf den ersten Blick eigentlich hier kein Unterschied gegenüber dem vorigen Screenshot. Sehen wir uns aber die Rowcounts (im folgenden Screenshot roter Kringel) an und scrollen wir beim CUBE ans Ende der Rowliste - da sehen wir einen gewaltigen Unterschied: 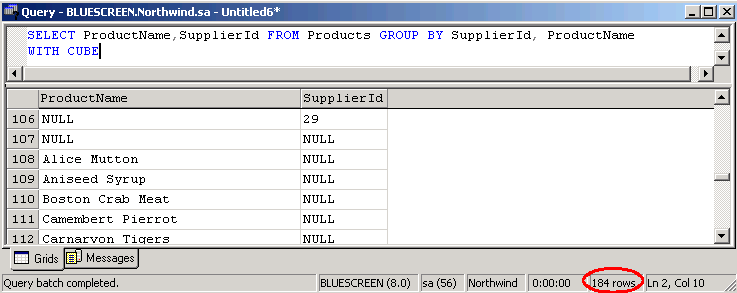
CUBE hat die Datenreihen die keine SupplierId besitzen, mit null ausgewiesen - das ist ja ok! Aber ROLLUP hat durch die hierarchische Ordnung diese "leeren" Felder nochmals gruppiert und angeordnet. Die HAVING ClauseDiese Clause wird üblicherweise mit der GROUP BY Clause kombiniert verwendet. Man verwendet sie quasi wie eine WHERE Clause in Verbindung mit der GROUP BY Clause - z.B. als ein Eingrenzungskriterum zur Gruppierung. Diese Annahme der Ähnlichkeit zur WHERE Clause bestätigt sich auch darin, daß sie ohne GROUP BY verwendet, sich auch wie diese verhält. Zu beachten ist, daß wie bei der ORDER BY Clause die Datentypen ntext, text oder image nicht zulässig sind. Die HAVING Clause nimmt folgenden Syntax: HAVING Kriterumsausdruck Wenn wir also unser erstes Beispiel recyclen und zusätzlich ein Eingrenzungskriterum anwenden, d.h. es sollen nur jene Produkte angezeigt werden deren Stückzahl unter 30 liegt, sieht das SQL Statement so aus: SELECT ProductName, SUM(UnitsInStock) AS 'Units In Stock' FROM Products GROUP BY ProductName HAVING SUM(UnitsInStock) < 30 Im Query Analyzer stellt sich dann so dar: 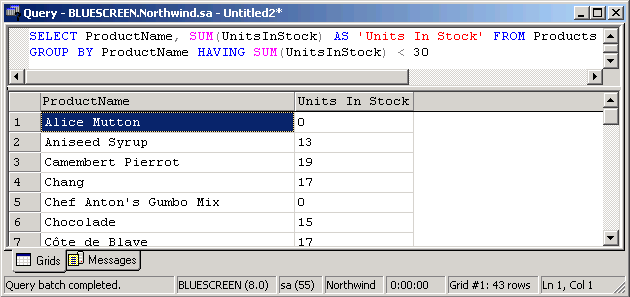
Wie erwartet tritt unsere gewünschte Einschränkung ein. SchlußbemerkungDieser Artikel sollte als Tutorial dienen um Ihnen anhand von einfachen Beispielen die beiden T-SQL Clauses GROUP BY und HAVING vorzustellen. Diese können sich bei der Gruppierung bzw. Auswertung von größeren Datenmengen als sehr nützlich erweisen. Verwandte Artikel
Aktualisieren von Daten mit dem UPDATE Statement Wenn Sie jetzt Fragen haben...Wenn Sie Fragen rund um die in diesem Artikel vorgestellte Technologie haben, dann schauen Sie einfach bei uns in den Community Foren der deutschen .NET Community vorbei. Die Teilnehmer helfen Ihnen gerne, wenn Sie sich zur im Artikel vorgestellten Technologie weiterbilden möchten.
Haben Sie Fragen die sich direkt auf den Inhalt des Artikels beziehen, dann schreiben Sie dem Autor! Unsere Autoren freuen sich über Feedback zu ihren Artikeln. Ein einfacher Klick auf die Autor kontaktieren Schaltfläche (weiter unten) und schon haben Sie ein für diesen Artikel personalisiertes Anfrageformular.
Und zu guter Letzt möchten wir Sie bitten, den Artikel zu bewerten. Damit helfen Sie uns, die Qualität der Artikel zu verbessern - und anderen Lesern bei der Auswahl der Artikel, die sie lesen sollten.
©2000-2006 AspHeute.com |
