Geschrieben von: Christoph Wille
Kategorie: Server
This printed page brought to you by AlphaSierraPapa
Auf Firmenwebsites finden sich sehr oft Dokumente im Adobe Acrobat PDF (Portable Document Format) Format, da sich mit ihnen das Layout über verschiedenste Plattformen hinweg bewahren läßt, womit sie ideal für Produktbeschreibungen oder Handbücher sind. Wie aber schafft man es, dem Besucher der Website die Inhalte dieser Dokumente in einem Suchformular zur Verfügung zu stellen?
Der einfachste Weg zum Erfolg ist sich auf den bewährten Index Server (bzw. Indexing Service) zu verlassen, der ja auch bei HTML Dokumenten zum Einsatz kommt, wie zum Beispiel hier auf AspHeute.com. Eine Klippe muß man allerdings umschiffen - der Indexing Service weiß nicht, wie er ein PDF Dokument indizieren soll. Dazu benötigt er etwas Hilfe, und zwar in Form eines sogenannten IFilters. Dieser stellt dem Indexing Service die Wörter der Dokumente zum indizieren zur Verfügung, agiert sozusagen als "Importfilter".
Dankenswerterweise stellt Adobe einen solchen IFilter auf ihrer Website zum Download zur Verfügung. Die aktuelle Version zum Zeitpunkt der Artikelerstellung war 4.1, und diese kann sowohl unter NT 4.0 als auch unter Windows 2000 installiert werden.
Nach dem Download stellt sich die Installation sehr unkompliziert dar. Einzig und allein der Indexing Service muß gestoppt werden:
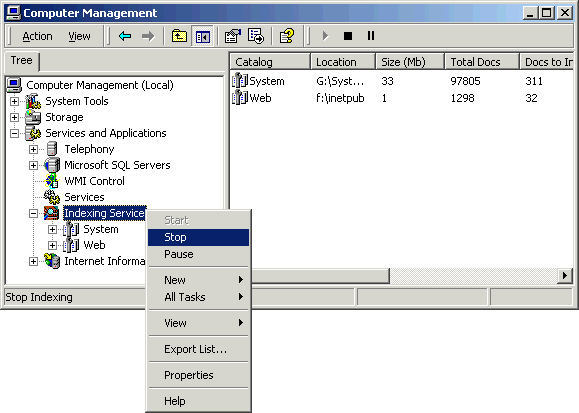
Danach startet man das Setup für den PDF IFilter, welches ohne Fragen (und hoffentlich Fehler) komplettiert. Nun kann der Indexing Service wieder gestartet werden.
War das schon alles?, werden sich nun einige fragen. Ja, es ist so einfach. Zum Beweis kopieren Sie einfach einige PDF Dokumente in ein Verzeichnis, das durch einen Index Server Catalog bedient wird (das Anlegen eines Catalogs wird im Artikel Arbeiten mit Index Server Catalogs beschrieben). Warten Sie ein wenig, damit Index Server die Dateien scannen kann, dann wählen Sie Query the catalog im MMC Snap-in aus, und setzen eine Abfrage ab:
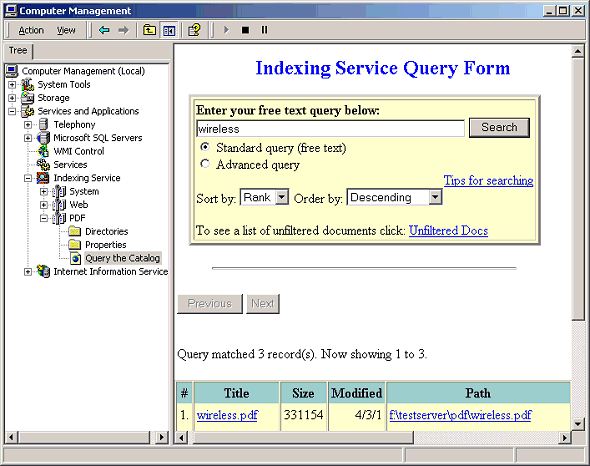
Nun werden nicht nur Resultate aus HTML Dateien angezeigt, sondern auch Resultate aus PDF Dateien. Mit Hilfe der Abfragesprache des Indexing Service kann man die Abfragen auch gezielt auf spezifische Dateitypen einschränken, um zB nur Produktbeschreibungen aus PDF Dokumenten als Resultat zu erhalten.
Man soll die Bordmittel des IIS und seiner zusätzlichen Services nicht unterschätzen. Oft kommt man damit weiter, als man im ersten Moment vermuten würde.
This printed page brought to you by AlphaSierraPapa
Arbeiten mit Index Server Catalogs
http:/www.aspheute.com/artikel/20000524.htm
Objektbasierte Index Server Suche
http:/www.aspheute.com/artikel/20010403.htm
Acrobat for Windows Downloads
http://www.adobe.com/support/downloads/acwin.htm
Searching the Contents of PDF Files on a Web Site
http://www.adobe.com/support/techdocs/12b42.htm
©2000-2006 AspHeute.com
Alle Rechte vorbehalten. Der Inhalt dieser Seiten ist urheberrechtlich geschützt.
Eine Übernahme von Texten (auch nur auszugsweise) oder Graphiken bedarf unserer schriftlichen Zustimmung.